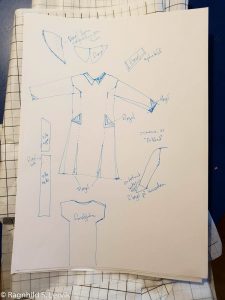
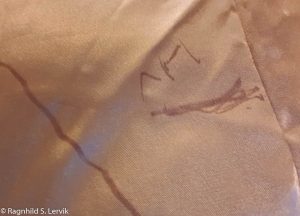Mønster og instruksjoner på tysk var jo et lite eventyr, så det første jeg gjorde var å kjøre instruksjonene gjennom Google translate og så gå gjennom og rydde opp i språket (særlig sømfagsord, Google var ikke så god på de) og sjekke at jeg faktisk skjønte hva som skulle gjøres. Så var det bare å sette i gang. Enkelte ting har jeg forenklet, jeg droppet løpegangen i livet og snor i hetta, til gjengjeld har jeg sydd refleksbiser i en del sømmer, for å sørge for god synlighet i mørket.
Jakka har vært flittig brukt i godt over et år, og passformen er super, så mønsteret kan jeg absolutt anbefale.
Nå spekulerer jeg på å sy softshelljakke til meg selv. Det finnes veldig mye kule stoftshellstoff der ute, mens det som finnes i butikkene av jakker til voksne stort sett er ganske kjedelige, ensfargede greier. Ikke har de innebygd refleks, heller. Vi får se mot høsten.
Ja, ikke i Norge (ennå), men antallet mennesker på verdensbasis som dekker til deler av ansiktet ute i offentligheten har helt klart gått opp. Og folk syr, og syr, og publiserer gratis mønster og how-to-videoer og resultatet er at jeg får lyst til å prøve. Burde vi gå med maske? Jeg vet ikke, men jeg tenker at jeg i alle fall skal være i forkant sånn at om det kommer en offisiell anbefaling så har vi masker liggende klare.
Tettvevd bomullsstoff er det anbefalte materialet, så jeg hentet opp et utvalg quiltestoffer fra lageret, kjøpt… fåglarna vet til hva. Fordi det var på tilbud? Fordi jeg synes mønsteret var fint? Fordi det er kjekt å ha? Vel, det er jo kjekt å ha nå. Til for fant jeg noen meter med bomull fra IKEA, Ditte i blått, kjøpt på grunn av et kostymeønske eldstemann hadde for noen år siden som det aldri ble noe av og som ikke er aktuelt lenger.
Mønster finnes det utallige av. Jeg har sett flere videoer, blant annet denne: Craft Passion – Official face mask sewing video tutorial. Hva som gjør den “official” er uklart, men den er grundig og tydelig. Metoden jeg har brukt for å lage kanal til neseklemme er derimot den samme som Lucky sew and sew beskriver i bloggversjon (ikke video). Hun forklarer også masseproduksjonsrutinen sin, om du skulle være interessert. Craft Passion har også mønster og foreslåtte variasjoner i denne bloggposten. Mine masker har altså både kanal til neseklemme og lomme til eventuelt ekstrafilter – kaffefilter er foreslått mange steder ser jeg.
Det mønsteret jeg faktisk har brukt i første omgang er nesten identisk som Craft Passion sitt og kommer fra Cricut. Har du en Cricut kan du bruke deres mønster til å kutte ut delene, men de har også en PDF for oss andre. Cricut sitt mønster er en smule større enn Craft Passion sitt, og siden det passer meg antar jeg de millimeterene trengs. Som neseklemme har jeg brukt dobbel piperenser og til snor “t-shirt yarn” (gjenbruk, yay) som enten kan knytes bak hodet eller til en hempe til å feste rundt ørene.
Opprinnelig hadde jeg tenkt å teste både denne “fasongsydde” typen maske og den andre varianten, firkantet stoffstykke med legg i siden. De fasongsydde sitter såpass godt at jeg er usikker på hva poenget med å teste de andre skulle være, men det er mulig riktig størrelse er viktigere med de fasongsydde, slik at om man skal sy til andre kan de med legg være smartere?
Nu vel. Samme hvilken maske du velger har den liten hensikt om du ikke bruker den riktig. Her er instruksjoner for hvordan ta på og av engangsmasker. De samme prinsippene gjelder for stoffmasker, men de skal selvsagt i skittentøyet og ikke i søpla (bare husk å fjerne et eventuelt filter). Siden viruset bukker under for såpe og vann skal normal klesvask holde, men bomull kan kokvaskes om man vil være på den sikre siden.
Video for å vise at masken sitter tett over nesa og at man altså faktisk puster gjennom den og ikke “rundt”:
Ellers fikk jeg jo igjen bevist for meg selv hvorfor jeg ikke syr ting for salg. Masseproduksjon ligger ikke for meg. Jeg klipte stoff til en 60-70 masker, men gikk lei og sydde bare ferdig ca halvparten. Så nå har jeg en bunke halvsydde liggende som ikke blir ferdigsydd med mindre det blir påbudt med maske.
Når vi flyttet inn i leiligheten vår i 2010 hadde vi bare to uker fra overtakelse til vi skulle være ute av den gamle leiligheten, derfor ble bare det aller nødvendigste av maling gjort. Etterpå har vi fikset noen flere vegger (fjernet brystningspanel og malt hvitt). Vindusveggen i stua var dekket av… treverk når vi flyttet inn. Radiatorene var bygd inn i kasser og den biten av vegg som ikke er dekket av vindu var dekket av trespiler, litt som på vinduslemmer, men altså spikret fast i veggen. På et eller annet tidspunkt fikk jeg nok og rev det hele ned. Vel og bra, men så skulle jeg jo liksom male veggen, og det… tok sin tid. I fjor (eller var det forfjor) sparklet jeg det som var av spikerhull og slikt, og hadde store intensjoner om å male også, men så kom vel livet i veien. Så sånn har det sett ut since forever:
Vakkert, eller hva? På toppen av det hele: Når vi flyttet inn hang vi opp gardinene vi hadde med oss fra den gamle leiligheten. Sånn inntil videre, liksom. De to lange seksjonene (som hadde vært tilpasset verandadøra) var akkurat for lange, så de sopte i gulvet. Og opphenget var ikke akkurat ideelt, vi arvet kirsch-skinnene (type U) med leiligheten, men på dem var glidere med klemmer (slike) og det går jo for all del an å henge gardiner i de, men når noen drar litt hardt i gardina rykkes den gjerne ut av en klemme eller to, så gardinene hang litt på snei til stadighet. Og det har de altså gjort i ti år. Ting tar tid.
Men nå er både vegg og vinduskarmer blitt hvite. Og det er så lyst og deilig at jeg er nesten ekstatisk. Det var ikke det minste fristende å henge opp igjen de gamle gardinene (med eller uten fikset oppheng og lengde). Så jeg tok en tur på stofflageret, og fant noen gardinlengder fra IKEA. Og noen meter rettsøm senere har vi lyse gardiner i sommer- (ok, da, vår-) sola.
Jeg hadde tre lengder av stoffet med kvistmønster og to av det med striper. Sistnevnte ble kjøpt med tanke på et annet rom for noen år siden, men aldri brukt. Kvistene hadde vi faktisk et sett sommergardiner av i den gamle leiligheten, men de ble hengende igjen til glede (tror jeg) for neste eier. Det er hele tre skinner montert der oppe bak gardinbrettet, så jeg har hengt gardinene i to lag. Og for å utnytte stoffet og få nok gardiner skjøtet jeg de to typene sammen i to lengder også, og det ble i grunn ganske stilig synes jeg selv.
Jeg har sydd rynkebånd på gardinene og hengt dem opp med “rynkebåndskrok”, eller “sånne gardinkroker som ser ut som flatklemte alfakrøller” som jeg beskrev det når jeg skulle spørre etter dem på Sommer (de hadde ikke, forøvrig, jeg kjøpte bånd der men måtte over gata til Wiig for å få kjøpt kroker).
Jeg er jo ikke så god til å planlegge, for jeg dro til byen for å kjøpe bånd og kroker uten å ha målt bredden på gardinene. Eh, gi meg ti meter bånd, sa jeg, det holder sikkert i massevis. Holdt gjorde det, men ikke akkurat i massevis…
Det er noe som heter “thread chicken”, det spiller jeg til stadighet. Rynkebåndschicken var nytt for meg.
Siden 2011 har vi hatt som fast tradisjon å fylle påskeegg med smågodt til alle (førskole)lærerene til ungene og dele ut siste dagen før påskeferien. I år ble det jo ikke sånn, kan du si. Men nå ligger det jo an til en gradvis åpning, yngstemann skal tilbake på skolen om en uke, og nettet (i alle fall min krok av det) har i ukesvis flommet over av “kaninposer”, og selv om det jo opplagt er ment som alternativ til påskeegg, så føles de ikke… like påskete? Så jeg gravde fram noen meter med egnet stoff fra lageret, fant et mønster på nett, sydde en test og gikk deretter i masseproduseringsmodus.
Metervis med kaninpose in progress: Her klippes ikke tråder mellom hver søm.
Jeg fulgte mønster og sømebskrivelse fra Creativ Company med en endring, jeg klippet utside og fór i en del hver, så slapp jeg sømmen i bunnen. 21 poser fikk jeg ut av disse to stoffbitene. Det er litt lite, så jeg får ta en runde til i kjelleren og ved maskina.
På testposen har jeg tegnet ansikt med tekstiltusj. Resten tenkte jeg ungene skulle få tegne på sjøl, og så må vi vel lage/skrive noen små kort med navn og vår-hilsen på. Posene trenger også en runde med strykejernet, men siden tusjen skal fikseres slår jeg to fluer i en smekk og presser ut sømmer samtidig da.
Jeg tenker at sånn som situasjonen er er smågodt lite aktuelt, så vi får finne noe godteri som er innpakket i år.
Jeg har forresten opprettet en egen instagramkonto for sømbilder (eller “fibercrafts” blir det nok). Jeg prøver å holde @Lattermild til å handle hovedsakelig om bøker, så da oppsto @lattermild_syr. Følg meg gjerne, og tips meg gjerne om andre jeg burde følge.
To av yndlingsbuksene revnet i løpet av en uke, og vinterjakka hadde plutselig gått opp i sømmen i siden. Vel, fram med symaskina.
Buksene fikk en lapp fra en fravokst barnejeans bak hullet holdt på plass av spraylim på boks (levninger fra jeg quiltet, har sett tips om at limstift funker fint om du ikke har spraylim) og så har jeg sydd frem og tilbake over lappen og hullet. Enkelt, men effektivt.
Det ene hullet på jakka var i sidesømmen nede, der sydde jeg på en bit reflekstape over hullet.
Det andre hullet var i sømmen under armen. Det synes jo ikke til vanlig, så der gjorde jeg det enkelt: Noen runder med sikksakksøm.
Fra før har jeg både sydd refleksbånd på ermer og andre egnede steder på denne jakka, og en rift har fått en mer fargerik lapp:
Å fikse klær har bare plussider fra mitt synspunkt, jeg sparer penger og miljø og ikke minst slipper jeg å gå på jakt etter nye klær. Jeg er ingen fan av klesshopping, og sliter alltid med å finne plagg der jeg liker både form, farge og funksjon, så når jeg først har funnet et plagg som funker er det om å gjøre å få det til å vare lengst mulig.
Ikke vet jeg hvorfor denne typen høytaler fra Jabra går under navnet “padde”, men siden den hadde samme kjælenavn hos forrige arbeidsgiver som hos nåværende er det nærmest vedtatt, den heter Padda. Problemet med Padda er at den er ganske anonym og har en tendens til å bli forlagt. Og når noen forlegger sin kommer de og vil låne vår. Og så blir den også forlagt. Og sånn starter hvert møte der noen skal delta via Skype (eller telefon) med en febrilsk leting etter en padde. Så når vi (det vil si teamet jeg jobber i) fikk hentet ut en ny padde fra IT etter at vår hadde forduftet nok en gang fant vi ut at vi skulle gjøre noe for å personliggjøre den, slik at det skulle bli vanskeligere å glemme hvem den var lånt fra og gjøre sjansen større for at den skulle finne veien tilbake dersom noen genuint glemte den på et møterom. Jeg foreslo at jeg kunne sy et nytt etui til den, i litt mer synlige farger enn det svarte som følger med fra fabrikken, og kanskje male teamnavnet vårt på den også (siden merketape har hatt tendens til å dette av etterhvert). En kollega foreslo at siden det var en padde burde etuiet se ut som en skilpadde, og siden jeg selvsagt tar en slik utfordring på strak arm er det nettopp det det ferdige etuiet ser ut som.
Sydd “fort og gæli” av quiltebomull fra stofflageret og en glidelås jeg hadde liggende, mønster aldeles etter eget hode og konstruert i farta. Øynene er et tillegg i regi nevnte kollega, men de er jo virkelig prikken over i’en.
Selve Padda har i tillegg fått “DVH” malt på seg med grønn, skimrende neglelakk.
Padda har ikke vært missing in action siden den fikk makeover, og nå nærmer det seg et år, så jeg vil kalle det en suksess.
Nei, jeg snakker ikke om å tøye ut (selv om jeg, i motsetning til Pondus, mener det kan være lurt innimellom), men når jeg først fikk dreisen på overlocken ble det jo riktig så gøy å suse avgårde i stofftyper jeg tidligere har forsøkt å holde meg unna. Dvs alle stoffer med strekk. Joda, det går an å sy pene plagg med strekk på vanlig maskin også, men jeg mistenker (vel: vet) at det krever tålmodighet, og som jeg og Linda pleier å si: Når de delte ut tålmodighet gadd vi ikke å stå i kø. Så, altså, det ble bare sånn passe de gangene jeg prøvde meg. Brukbart, men ikke så bra som jeg hadde tenkt. Og så tar det laaaaaaaang tid å sy falsk overlocksøm med vanlig maskin (i alle fall min vanlige maskin), og da er vi tilbake til det med tålmodighet igjen.
Nuvel. Om du leser bokbloggen har du allerede hørt om noen av resultatene fra de senere måneders innsats, siden jeg har benyttet sjansen til å omtale noen av sybøkene jeg har brukt mønster fra. Men her kommer litt bilder.
Seksåringen er dinosaurfrelst. Vi har kjøpt både bukser og gensere med dinosaurer på i gutteavdelingen på H&M, hun bryr seg heldigvis ikke (i den grad hun overhodet legger merke til det) om at det bare er i gutteavdelingen man finner dinosaurer. Det er vel ikke noen stor nyhet for faste lesere at jeg synes de kunne droppet hele inndelingen og latt folk (unger!) velge det de ville selv, men der er vi altså ikke, selv i 2019.
Jeg innså når jeg skulle redigere bildet at hun har på kjolen bak frem, så dere får ikke se lommene. Ja, ja.
Da er det desto hyggeligere å sy selv. Jeg fant verdens kuleste dinosaurstoff på Stoff og stil, og siden ungen var med på handleturen fikk hun velge hva jeg skulle sy, og da kom det ønske både om bukse og om kjole. Det falt seg sånn at jeg hadde både kjole- og buksemønster jeg hadde lyst til å teste, så litt etter litt kom hele antrekket på plass. Buksa ble sydd etter mønster fra Nostagisk søm: Bare blåbær bukse. Kjolen er Kløverkjole med lommer fra Heilt spesiell og Jubel. Ribb til begge er kjøpt hos Klar, ferdig, sy!
Halsløsningen på kløverkjolen er ikke optimal, så jeg har kjøpt mer ribb og planlegger å fikse på den. Jeg må bare få sneket kjolen ut av grepet til seksåringen først.
Jeg hadde tatt i litt når jeg kjøpte stoff, det har jeg en lei (eller heldig) tendens til å gjøre. Så når jeg skulle sy barselgave til den nyankomne babyen til venner av oss ble det dinosaurbukse der også, og så sydde jeg en bukse til etter Bare blåbær-mønsteret til storesøsteren for godt monn. Sistnevnte har visst nesten nektet å la buksa vaskes etter at hun fikk den, det er visst den mest komfortable buksa ever, i følge henne.
Nå er det bare smårester igjen, så nå får det bli prematur- eller dukkeklær av det siste.
Bare blåbær bukser blir det fler av. Jeg har klippet to til til de aktuelle seksåringene i et annet kult stoff jeg hadde liggende. Men jeg får vel også gjøre et forsøk på å modifisere mønsteret litt så buksene får lommer. Lommer må man ha.
Et annet mønster fra Heilt spesiell og Jubel, Gul bukse, brukte jeg til et lite redesign-prosjekt. Eldstemann hadde kjøpt en hettegenser på loppemarked som hen i etterkant ikke helt selv forso hvorfor var blitt med i posen. Den var nemlig størrelse XXL og rååååsa.
Hva var det hen tenkte?
Men seksåringen liker råååsa, og det var mye stoff i genseren, så den virket som et bra utgangspunkt for saks og nål.
Dette klassifiserer vel mer som gjenbruk enn redesign, siden jeg rett og slett klippet bort alle sømmer for å få størst mulig flate stoffbiter å jobbe med (ved redesign anser jeg at noe av poenget er å bruke elementer fra det opprinnelige plagget).
Her må det skjøtes.
Mye stoff var det, men ingen av bitene var lange nok til å bli bukseben uten skjøting. For å gjøre det mer interessant kjøpte jeg en liten bit jersey med bevingede enhjørninger (eller alicorns, som jeg etterhvert har lært at det heter) og lagde tittekanter i skjøtene og brukte det også på lommene.
Igjen bak fram, men her ser dere da lommene siden bildet er tatt fra siden…
Også denne buksa ble godt mottatt hos “kunden”. Noen småfrustrasjoner rundt mønsteret og instruksjonene har jeg allerede delt på bokbloggen.
Selv om jeg har kommet i gang med å bruke overlockmaskina som jeg kjøpte for noen av forsikringspengene høsten 2017 (og ikke rørte før sensommeren 2018…) hadde jeg ikke våget meg på noe annet enn rett-fram firetråds overlocksøm. Jeg har riktignok lært meg å tre den, men det var mer av nød enn lyst, siden tråden røk. For å bli litt bedre kjent med maskina meldte jeg meg derfor på enkveldskurs hos Klar, ferdig, sy! (som også er der jeg har kjøpt maskina) i begynnelsen av februar. Dagen kom litt brått på meg, men jeg fikk nå pakket med meg maskina og en stoffbit jeg hadde liggende og møtte opp. Vi fikk demo av litt forskjellige teknikker, så fikk vi noen oppgaver som ga oss mulighet til å teste teknikkene selv, og så var det fritt fram å sy et plagg, avbrutt av et par demoer til (blandt annet av “hvordan sprette overlocksøm”, utrolig nyttig å kunne).
Stoffet jeg hadde med var et impulskjøp fra Stoff & stil som jeg hadde tenkt å sy genser eller kjole til seksåringen av. Mønster hadde jeg ikke tenkt på, men de har heldigvis et utvalg i butikken (noe jeg selvsagt visste), og jeg endte med et kjolemønster fra Ottobre. Etter å ha tegnet av rett størrelse og klippet stoffet var det bare å sette i gang og sy.
Flatlock synes utenpå og gir en litt røffere effekt.
Siden en av teknikkene vi hadde lært var flatlock benyttet jeg muligheten til å teste det i et plagg, og sydde derfor raglansømmene med flatlock. I tillegg fikk vi se eksempel på bruk av perlefot for å sy på perlebånd, så da måtte nesten det testes også. Det var litt træl, særlig å starte og stoppe pent, men det ble tatt godt i mot av mottakeren.
Jeg innså riktignok i etterkant at det kanskje var begrenset lurt å sy perlebåndet nederst på akkurat denne kjolemodellen, siden det gjør at nederkanten ikke er elastisk, men det får så være, da har jeg lært det. Stikningene langs halsen og nede er forresten sydd med min gamle, trofaste Husqvarna, med tvillingnål, bare så det er sagt.
Ferdig kjole
Det neste prosjektet jeg satt i gang med var stoffvekter. Jeg har egentlig lenge planlagt å få tak i noe jeg kunne bruke til det, store muttere er en vanlig løsning, men så var det noen som lenket til denne oppskriften hos Ida Victoria på en av Facebookgruppene jeg henger på, og det var jo en veldig grei løsning. Jeg fant fram en bit restestoff fra Gambia, den måtte riktignok strykes først, så da fikk jeg testet det nyinnkjøpte bordstrykebrettet fra IKEA, som jeg ELSKER.
Deretter var det å kutte biter på 9×19 cm. Tilfeldigvis viste det seg at stoffbiten min var akkurat 45 cm bred når den var renskåret litt, så jeg fikk maks utnyttelse av bredden.
“Lag mange stoffvekter mens du er i gang, så du har nok til de neste syprosjektene dine!” oppfordrer Ida Victoria, og jeg synes tydeligvis det hørtes ut som en god idé, for jeg endte med hele 20 vekter. Det var kanskje litt i overkant, men bedre med et par for mye enn akkurat en for lite. Jeg vurderer å sy en pose å ha dem i av resten av den fargerike stoffbiten.
Om du ikke har hørt om stoffvekter før brukes de altså til å holde mønster og stoff på plass når du skal klippe (eller skjære). Slik:
Særlig på litt glatte og/eller elastiske stoffer er det bedre enn å nåle fast mønsteret (ikke minst sliter det mindre på mønsteret).
Nå er jeg for lengst i gang med neste prosjekt (faktisk nesten ferdig, det mangler bare den siste finishen med tvillingnål, men jeg brakk den ene jeg hadde i går og måtte derfor kjøpe nye i dag). Men det er bare bra at jeg har planer for ting jeg skal sy, for om bare noen få uker skal jeg på sytreff (også i regi Klar, ferdig, sy!), og da må jeg jo ha noen prosjekter.
Jeg er her fortsatt, det er jo ikke ille bare det? Jeg er ferdig med behandling og tilbake i jobb (100 % siden august). Ny jobb, til og med, det er jo ikke så ille når man blir headhuntet midt i en langtidssykemelding?
Håret har grodd tilbake. Med krøller! Når jeg var 10 ønsket jeg meg krøller, men nå må jeg innrømme at jeg ikke helt vet hva jeg skal gjøre med dem. Men så rullet et bilde av en superskurk over feeden min mens jeg holdt på å sy ferdig “trollmannskapper” til både meg selv, eldstemann og et par venner til Halloween (jada, jeg burde selvsagt lagd et innlegg om dem også) og man kunne formelig se lyspæra som sa “Pling” over hodet mitt:
Så nå er jeg i gang med mitt første cosplay til meg selv. Målet er å bli ferdig før krøllene forsvinner…
Jeg har funnet de perfekte rosa stoffene på Stoff og stil og har lett etter mønster i de bladene jeg vanigvis leter i (noen årganger med Ottobre, blant annet) og ikke funnet noe som var i nærheten, så da var det bare å sette i gang og tegne selv.
Versjon en ble klippet og sydd av en forrest jeg hadde liggende, og det var lurt, for her var det flere ting som ikke stemte helt. Jeg tok like gjerne og tegnet korreksjoner rett på stoffet når jeg prøvde. Jeg brukte en ny merkepenn, som visstnok skal forsvinne av seg selv etter en stund. Gjør den ikke det er det ikke så farlig, stoffet skal vel likevel mest sannsynlig til gjenvinning, men så får jeg jo testet det med det samme.
Bommet litt på brystpunktet, gitt.
Ikke alt blir like tydelig når man forsøker å skrive på et plagg man har på seg (uten å dra for mye i det også), men jeg tror jeg klarte å tyde mine egne kråketær (jeg var lur nok til å gjøre skikkelige notater og mønsterkorreksjoner med en gang og ikke satse på at jeg skulle huske hva jeg hadde ment neste dag).
Her står det “LIV”, rai, rai.
Så nå har jeg et korrigert mønster. Og nå lurer jeg på om jeg skal tørre å klippe i det egentlige stoffet, eller om jeg skal sy en test til. Jeg tror det blir det første. For det første var det ikke så fryktelig dyrt, så om jeg må kjøpe mer er det ikke totalt krise. For det andre tror jeg at jeg vet hvordan jeg skal sy for å sikre at jeg kan fikse eventuelle problemer underveis.
Nei, jeg sitter nå her, både stuptrøtt og lys våken og klokka er ti på tre om morran. Det er mulig det er en bivirkning av en eller annen av medisinene jeg får i meg for tiden, legen snakket om fare for mareritt ifm den ene typen kvalmestillende og da er kanskje ikke søvnforstyrrelser en umulighet, selv om jeg ikke fant noe om det i pakningsvedlegget. Eller så er det kanskje bare helt normal insomnia, noe jeg tross alt ikke er fremmed for fra før (men da som regel i mer akutte stressituasjoner, før reiser f.eks.). Det skjedde tidligere denne måneden også, jeg var våken flere timer midt på natten og fikk blant annet utnyttet tiden til å fikse noen bilder som minstemann skulle ha med i barnehagen. De har timestamp, så jeg kan fastslå at det var 6. september. Siden cellegiftkuren går i treukerssykluser betyr det at det var i en heeeelt annen fase av syklusen enn jeg er i nå Sånn går det når man forsøker å telle uker midt på natten, 6. september er jo ganske nøyaktig tre uker siden, når jeg tenker meg om. Jeg fikk cellegift mandag 4. september og igjen nå på mandag, så da er det vel nærliggende å tro at søvnløshet halvannet døgn senere ER en bivirkning (enten av cellegiften eller de kvalmestillende, ikke greit å vite).
Ellers? Jeg har altså nettopp fått cellegift, det var runde tre av fire av den første typen jeg skal ha. Etter det følger en annen type, som også går over tolv uker, enten hver tredje uke som nå, eller hver uke, dersom mengden bivirkninger skulle tilsi at lavere dose hyppigere er bedre for meg. Legen mener svulsten har minket, så det må jo være positivt, og de har satt inn en markør “i tilfelle den blir så liten at de ikke finner den” fikk jeg forklart. Jeg skal altså ha kirurigi etter cellegiften og så følger det stråling etter det.
I denne runden med cellegift har jeg hatt flaks og hatt særdeles lite bivirkninger. Energinivået er lavt, særlig første uka etter kur, men siden jeg er 100 % sykemeldt kan jeg ta det med ro ved behov og prøve å fordele ting som må gjøres utover ukene, og plassere større aktiviteter etter tidspunkt i syklusen der det er mest sjanse for ok med energi. Jeg har en arbeids- og oppdragsgiver som begge er ekstremt fleksible, så jeg har kunne jobbe litt (noe sånt som et dagsverk eller halvannet i måneden), noe som både gir meg avkobling fra “å være syk” og holder hodet såpass koblet til jobb at jeg ikke mister kontakten totalt, og derfor føles lurt, planen er jo tross alt at jeg skal gjennom dette og kunne komme tilbake i full jobb. Alle timer jeg jobber rapporteres selvsagt som jobb, også til NAV slik at det ikke skal bli noe krøll i utbetalinger.
Ellers går jeg nå rundt og diller og bedriver hobby, for det meste. Det blir tid til å lese litt, men siden jeg falt for fristelsen til å begynne på den niende (?) gjenlesingen av Patrick O’Brians Aubrey/Maturin-serie, som bare er på 20 relativt tykke bøker blir det ikke så… produktiv lesing. Men det er greit.
Håret begynte å dette av siste uka i første syklus, jeg trakk hånda gjennom og satt plutselig med en håndfull. Da gjorde jeg kort prosess og gikk løs med saks, klippemaskin og barberhøvel.
De bomullsluene jeg allerede hadde begynt å sy har så langt vært det som har funket best, synes jeg. Det har blitt en del fler av dem, og fler skal det bli (jeg har akkurat fått en pakke fra Spoonflower med noen kule bok- og Dr Who-tema stretchstoff), så jeg kan variere mønster etter humør, akkurat som jeg velger t-skjorter etter humør. Parykk slo jeg egentlig fra meg før jeg fikk tilbudet. Jeg ser ikke for meg at det er noe jeg ville komme til å bruke overhodet, og da virker det meningsløst at velferdssamfunnet skal betale flere tusen (ikke at jeg vet hva en skikkelig parykk koster) for det. Jeg var innom og kikket på utvalget “hodeplagg” de har på frisøren på St. Olavs som mulig alternativ, men slo fort fra meg dem også, de var alt for damete for meg. Da er det uendelig mye morsommere å sy selv.
Jeg har forresten kjøpt parykk, jeg skal da ikke sitte her å lyve heller, men den kostet 199 kroner på Standard i Oslo og er knallblå. Jeg tenkte kanskje til festbruk?